
OpenEvidenceの日本担当前田です。
医療現場で生成AIを使うときに、こんな疑問はありませんか?
- 「ChatGPTを医療現場でそのまま使っても大丈夫なのか」
- 「AIの回答に、医学的な根拠を持たせるにはどうすればよいのか」
結論からいうと、医療用生成AIでは「RAG(検索拡張生成)」の考え方が重要です。
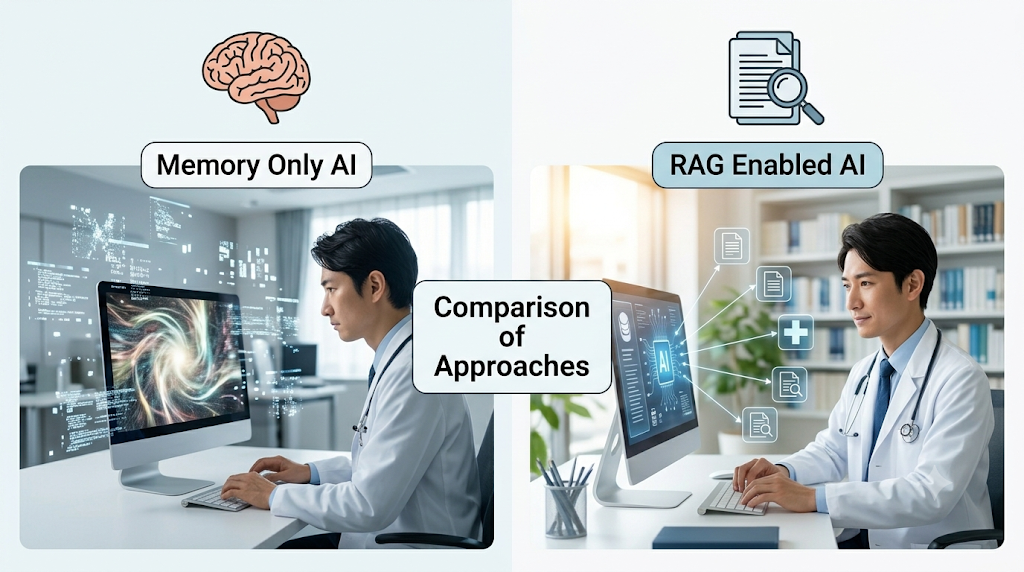
RAGとは、AIが自分の記憶だけで答えるのではなく、外部の信頼できる文献、診療ガイドライン、添付文書などを検索し、その内容をもとに回答を作る仕組みです。
つまり、医療AIを「記憶だけで答えるAI」から、根拠を確認しながら答えるAIに近づける技術です。
本記事では、RAGがなぜ医療AIに必要なのか、ハルシネーションをどう抑えるのか、臨床現場で導入する際の注意点を解説します。
前提から知りたい方は、エビデンスベースAIとは?も参考にしてください。
医療における生成AIでRAGの考え方が重要な理由
- 生成AIのハルシネーションが持つ臨床リスク
- エビデンスベースの医療を支えるRAGの仕組み
- 医療の生成AI利用においてRAGが必須となる理由
- ガイドラインが求めるセキュリティとデータ保護
医療で生成AIを使うなら、RAGの考え方がとても重要です。
理由は、医療ではAIの回答が、患者説明や診療記録、薬の確認、治療方針の検討に使われる可能性があるからです。
一般的な生成AIは、読みやすい文章を作るのが得意です。
しかし、その内容が最新の医学論文や診療ガイドライン、薬の添付文書に基づいているとは限りません。
つまり、医療では「それっぽい回答」だけでは不十分です。
大切なのは、次の3つです。
- その回答は、何を根拠にしているのか
- 医師や薬剤師が、元の情報を確認できるのか
- 最後の判断を、医療者ができる形になっているのか
RAGは、この3つを支えるための仕組みです。
簡単にいうと、RAGはAIに「自分の記憶だけで答えさせる」のではなく、信頼できる文献や診療ガイドラインを確認してから答えさせる方法です。
そのため、医療用生成AIではRAGが重要になります。
生成AIのハルシネーションが持つ臨床リスク

生成AIを医療現場で使うときに、特に注意したいのがハルシネーションです。
ハルシネーションとは、簡単にいうとAIの知ったかぶりです。
AIが、事実ではない情報を、まるで正しい情報のように答えてしまうことがあります。
たとえば医療では、次のようなリスクがあります。
- 存在しない論文を引用する
- 薬の用量を誤って説明する
- 古い診療ガイドラインをもとに回答する
問題は、AIの文章がとても自然に見えることです。
そのため、間違っていても気づきにくい場合があります。
一般的な文章作成なら、多少のミスはあとで直せます。
しかし医療では、誤った情報が患者説明や診療記録に使われると、医療安全上の問題につながる可能性があります。
だからこそ、医療用生成AIには、AIが勝手に答えるのではなく、根拠となる文献やガイドラインを確認できる仕組みが必要です。
エビデンスベースの医療を支えるRAGの仕組み
RAGは、医療におけるエビデンスベースの考え方と相性が良い技術です。
なぜなら、RAGはAIが回答する前に、外部の信頼できる情報源を検索し、その内容をもとに回答を作る仕組みだからです。
通常の生成AIは、モデル内部に学習された知識をもとに回答します。一方でRAGでは、ユーザーの質問に対して、まず外部のデータベースを検索します。そして、検索された文献、ガイドライン、添付文書、院内文書などを参照しながら回答を生成します。
つまり、RAGはAIに「記憶だけで答えさせる」のではなく、「根拠となる資料を確認させてから答えさせる」方法です。
医療分野では、検索対象として次のような情報源が考えられます。
- 査読付き医学論文
- ガイドライン
- 医薬品添付文書
- 医薬品安全性情報
これにより、AIが不確かな内部知識だけに依存するリスクを下げることができます。
ただし、RAGはハルシネーションを完全に排除する技術ではありません。
そのため、医療用途では、RAGを導入するだけでなく、情報源の品質管理、検索精度の評価、引用表示、人間による最終確認を組み合わせることが重要です。
医療の生成AI利用においてRAGが必須となる理由

医療AIでRAGが重要な理由は、AIの回答に出典をつけやすいからです。
医療では、AIが自然な文章を作れても、それだけでは不十分です。
たとえばAIが「この治療法が推奨されます」と答えたとします。
このとき医師が確認したいのは、「その根拠は何か」です。
根拠が見えないままだと、AIを信じすぎてしまうリスクがあります。
逆に、根拠を確認できなければ、現場では使いにくくなります。
RAGを使うと、AIの回答とあわせて、参照した文献、診療ガイドライン、添付文書などを表示しやすくなります。
つまり、医師はAIの回答をそのまま受け入れるのではなく、元の情報を確認したうえで判断できます。
このように、情報の出所をたどれることをプロベナンスと呼びます。
RAGは、AIに判断を任せる技術ではありません。
医療者が根拠を確認して判断するための技術です。
ガイドラインが求めるセキュリティとデータ保護
医療機関が生成AIを導入する場合、セキュリティとデータ保護の設計が欠かせません。
理由は、電子カルテなどの診療データには、個人情報や要配慮個人情報が含まれるためです。
特に、個人アカウントで利用する汎用AIに、患者情報をそのまま入力することは避けるべきです。
医療機関で生成AIを扱う場合は、厚生労働省の「医療情報システムの安全管理に関するガイドライン」や、HAIPの「医療・ヘルスケア分野における生成AI利用ガイドライン」などを踏まえ、運用ルールを整える必要があります。
実務上、特に重要なのは次の観点です。
- 患者情報を外部に送信する範囲
- 入力データがAIモデルの再学習に使われるか
- 誰がAIを利用できるか
- 入力・出力ログをどう管理するか
- 院内規程や契約上の責任分界をどう整理するか
RAGは、こうしたセキュリティ設計とも関係します。
ただし、オンプレミスだから安全、RAGだから安全、という単純な話ではありません。重要なのは、データの流れ、権限管理、ログ管理、再学習利用の有無、ベンダー契約を含めて設計することです。
医療AIにおけるRAGは、信頼性だけでなく、情報管理とセキュリティの観点からも重要な技術基盤です。
医療の生成AI利用とRAGによる信頼性担保の仕組み

- 教科書を見ながら解くようにエビデンスを担保
- 臨床ガイドラインや信頼できる文献検索との連携
- 医師の意思決定を支援する確実なプロベナンス
教科書を見ながら解くようにエビデンスを担保
RAGの仕組みは、「教科書を見ながら問題を解く」アプローチに近いです。
汎用生成AIを単体で使う場合、AIは過去に学習した知識や言語パターンをもとに回答します。これは、記憶だけで試験問題を解くような状態です。
一方でRAGでは、質問に対して、まず外部の知識ベースを検索します。そして、見つかった資料を参照しながら回答を作ります。
これは、教科書やガイドラインを開いて、該当箇所を確認しながら答える状態に近いです。
医療では、この違いが非常に重要です。
なぜなら、医療情報は常に更新されるからです。モデル内部の知識だけでは、最新のガイドライン改訂、新薬承認、添付文書変更、安全性情報を反映できない場合があります。
RAGでは、外部データベースを更新することで、AIが参照する情報を新しく保ちやすくなります。
また、RAGの周辺技術として、ベクトル検索、リランカー、ナレッジグラフなどがあります。
ベクトル検索は、質問と文書の意味的な近さをもとに関連情報を探す技術です。
リランカーは、検索結果の中からより関連性の高い文書を選び直す技術です。
ナレッジグラフは、疾患、薬剤、検査、症状、禁忌などの関係性を構造化する技術です。
これらを組み合わせることで、単なるキーワード検索よりも、医療文脈に合った情報を探しやすくなります。
ただし、どれだけ高度な検索技術を使っても、最終的な臨床判断は医療者が行う必要があります。
RAGは、医療者が根拠へ早く到達するための補助技術です。
臨床ガイドラインや信頼できる文献検索との連携

RAGの実務上の強みは、臨床ガイドラインや信頼できる文献データベースと連携しやすいことです。
医療情報は変化し続けます。AIモデル自体を何度も再学習するには、大きなコストと時間がかかります。
しかしRAGであれば、外部の知識ベースを更新することで、AIが参照する情報を比較的新しく保ちやすくなります。
たとえば、次のような情報源と接続できます。
- PubMedなどの医学文献データベース
- 学会診療ガイドライン
- 医薬品添付文書
- 医薬品安全性情報
- 院内プロトコル
- 電子カルテ内の過去記録
また、医療文書作成の領域でも、生成AIの活用が進んでいます。
NECと東北大学病院の実証では、電子カルテ情報をもとに紹介状や退院サマリーなどの要約文章を生成し、作成時間を平均47%削減したと報告されています。
この取り組みでは、生成された要約文に電子カルテの引用元を関連付けて表示し、医師が根拠を確認できる設計も紹介されています。
このような事例は、RAGそのものに限定されるわけではありません。
しかし、医療AIにおいて「生成結果の根拠を確認できること」が実務上重要であることを示しています。
医療現場では、AIが文章を作るだけでは不十分です。
作成された文章の根拠を医療者が確認できることが、信頼性を支える重要な条件になります。
RAGの考え方を取り入れたエビデンスベースAIの例

RAGの考え方は、すでに医療AIサービスにも取り入れられ始めています。
たとえば、OpenEvidenceは医学文献や専門コンテンツをもとに、臨床質問への回答を支援する医療AIです。
Cochrane Evidenceとの連携も発表されており、信頼できる医学情報をもとに回答を支援する例として参考になります。
詳しくOpenEvidenceを知りたい方は別記事「OpenEvidence完全ガイド」も参考にして下さい。
UpToDate も、エビデンスベースAIの代表例です。UpToDateの専門家監修コンテンツをもとに、臨床質問への回答を支援する設計になっています。
ClinicalKey AIは、Elsevierのエビデンスベース臨床コンテンツを検索し、引用や参照元を示しながら回答を支援するサービスです。
これらのツールに共通しているのは、AIが自分の記憶だけで答えるのではなく、信頼できる医学情報に基づいて回答を支援する点です。
ただし、どのツールもAI単独で診断や治療を決めるものではありません。最終的な判断は、医師や薬剤師などの医療者が行う必要があります。
医師の意思決定を支援する確実なプロベナンス
RAGは、医師の意思決定を支援するうえで、プロベナンスを確保しやすい仕組みです。
プロベナンスとは、情報の起源と派生をたどれることです。医療AIでは、AIがどの文献、どのガイドライン、どの記録を参照して回答したのかを確認できることが重要です。
米国FDAのCDSソフトウェアガイダンスでは、医療従事者が推奨内容の根拠を独立してレビューできるかどうかが、Non-Device CDSとして整理されるうえで重要な観点の一つとされています。
これは日本国内の制度とそのまま同じではありません。しかし、医療者がAIの出力根拠を確認できる設計は、日本の医療現場でも、責任分界と安全性の観点から重要です。
国内でも、生成AIを医療現場に組み込む取り組みが進んでいます。
たとえば、TXP Medicalと大阪大学医学部附属病院の共同開発では、院内オンプレミス環境のローカルLLMを用いて電子カルテ情報を解析・構造化し、治験用電子ワークシートへ自動登録する機能が紹介されています。
患者情報を院外に出さずに処理する設計であり、医療AIにおけるセキュアな運用例として参考になります。
また、製薬企業や医療機関では、社内SOP、治験文書、メディカルライティング、症例情報整理などに生成AIやRAGを活用する動きも広がっています。
AIが情報を整理し、根拠を提示し、医療者や担当者が確認する。
この人間介在型の運用が、医療AIでは不可欠です。RAGは、この人間介在型の運用を支える技術とも言えます。
まとめ:RAGは医療AIの信頼性を支える考え方
RAGは、医療AIの信頼性を支える重要な考え方です。
理由は、AIの回答を「それっぽい文章」で終わらせず、信頼できる文献や診療ガイドライン、添付文書などの根拠に近づけられるからです。
この記事のポイントをまとめると、次のとおりです。
- 汎用生成AIは、自然な文章を作るのは得意だが、医学的に正しいとは限らない
- 医療現場では、ハルシネーションが患者説明や診療記録に影響する可能性がある
- RAGは、AIが外部の信頼できる情報源を検索し、その内容をもとに回答する仕組み
- RAGを使うことで、文献・診療ガイドライン・添付文書などの根拠を確認しやすくなる
- ただし、RAGがあればAIが完全に安全になるわけではない
- 最終的な判断は、医師や薬剤師などの医療者が行う必要がある
つまり、RAGはAIに判断を任せるための技術ではありません。
AIが根拠を探し、整理し、提示する。
医療者がその根拠を確認し、患者ごとの状況に合わせて判断する。
この役割分担を支えるのが、医療AIにおけるRAGの本質です。
医療AIに求められるのは、ただ速く答えることではありません。
根拠を示し、確認でき、医療者が責任を持って判断できることです。
その意味でRAGは、エビデンスベースAIを実現するための中核的な考え方だといえます。
なお、RAGを含めた医療AI全体の考え方については、エビデンスベースAIとは?で詳しく解説しています。